Ganz nach McLuhan sind es heute in wachsender Anzahl die Algorithmen, die uns massieren. Gefüttert werden sie mit Daten. Das jedenfalls ist fester Bestandteil dessen sein, was wir unter dem Stichwort Open Culture erleben. Wenn aber Algorithmen massieren, dann bitte mit der notwendigen Freiheit im Hintergrund. Wie sehr das auch die Kultureinrichtungen betrifft, wird in einem Gemeinschaftsprogramm von Wikimedia Deutschland, Deutsche Digitale Bibliothek, Open Knowledge Foundation Deutschland und der Servicestelle Digitalisierung Berlin deutlich.
Coding da Vinci heißt das Programm und möchte herausfinden, „was passiert, wenn Kulturinstitutionen mit der Entwickler-, Designer- und Gamescommunity ins Gespräch kommen und aus frei nutzbaren Kulturdaten neue Anwendungen, mobile Apps, Dienste, Spiele und Visualisierungen umsetzen“, so die Webseite. Anders formuliert: in den Kultureinrichtungen schlummern Schätze, nicht etwa, weil keiner hingehen würde, um sie zu sehen, sondern weil für Vieles noch immer der richtige Zugang gefunden werden muss. Zugang der vielleicht über neue Algorithmen heraus gefiltert oder geschaffen werden kann.
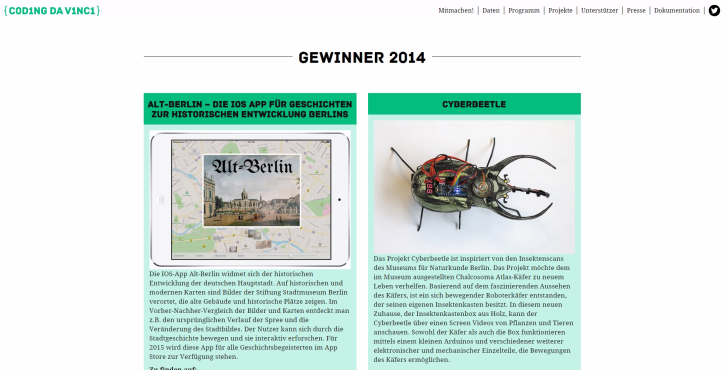
Im Sommer 2014 fand Coding da Vinci das erste Mal statt. Beteiligt haben sich 16 Kultureinrichtungen, die ihre Datenschätze unter einer Freien Lizenz und damit auch generell, also auch nach dem Ende der ersten Challenge zur Verfügung stellen. Heraus gekommen sind Projekte wie der zzZwitscherwecker, der uns nur Weiterschlafen lässt, wenn wir auf Alarmsignal hin den Vogel am Gesang erkennen. Grundlage waren Tierstimmen des Museums für Naturkunde Berlin und Wikipedia-Einträge. Aus einer Namensliste, bibliografischen Angaben und Lexika-Inhalten entstand die Webseite Verbrannte und Verbannte, die die Liste der im Nationalsozialismus verbotenen Publikationen und Autoren umfänglich näher bringt.
Coding da Vinci beschreibt sich auch als ein so genannter „Kultur-Hackathon“ und ist eine Art Wettbewerb um die besten Ideen. In einem 10-wöchigen „Sprint“ programmieren, basteln und gestalten rund 100 Entwickler und Designer ihre mit offenen Daten betriebenen Ideen und bringen sie zur Umsetzung. Eine Crowdfunding-Kampagne soll jetzt dabei helfen, dass die Daten schon vorher aufbereitet werden können. Die werden zwar von beteiligten Partnern unter einer Freien Lizenz zur Verfügung gestellt werden, was aber nicht gleich heißt, dass sie dann auch in einem Format vorliegen, welches diese sofort einsetzbar macht.
Gerade weil wir gesehen haben, wie viel Zeit die sich in ihrer Freizeit engagierenden Programmierer für die Aufarbeitung der Daten verwenden mussten, haben wir jetzt die Startnext Kampagne gestartet, um so im Vorfeld die Daten leichter zugänglich zu machen, die von den Kultur- und Gedächtnisinstitutionen zur Verfügung gestellt werden. (Barbara Fischer, Kuratorin für Kulturpartnerschaften bei Wikimedia Deutschland e.V.)
Mindestens 10.000 Euro brauchen die Initiatoren, um die Daten „polieren“ zu können. Hier geht es zu Crowdfunding-Seite.